Table of Contents
Install Decisions

Last meeting we had an install-fest to help new users get Linux installed on their computers. I would like to make a couple of comments on that experience. All three of the computer brought in were old computers with small memory. Now consider this, I doubt if any of those computers could have run Windows XP, or even Window 2000. The fact that Linux will run on them at all is a feather in it’s cap. But it is hardly fair to compare Linux running on those boxes to Windows running on a newer box. I doubt if any of you are interested in running a command line only system. If you only want a command line, load Cygwin and use it under Windows.
At the meeting before last, I spoke of how to move from Windows to Linux by making decisions. I am not going to repeat that here, if you have forgotten, check out, How to Transition from Windows to Linux. Instead I am going to discuss some other issues which come up when doing an install.
What is the Difference between a Workstation and a Server?

Lets start off by looking at a definition of Servers and Workstations as found in Merriam Webster Online Dictionary.
Workstation:
2: an intelligent terminal or personal computer usually
connected to a computer network b: a powerful microcomputer
used especially for scientific or engineering work
Server:
6: a computer in a network that is used to provide services
(as access to files or shared peripherals or the routing of
e-mail) to other computers in the network
Now lets see what some other people/places have to say about the difference between a server and a workstation.
Sometimes the right server is just a PC.
A server is designed and constructed differently from a PC. The
main considerations for server design are the need to handle
sustained loads for long periods of time and to monitor and manage
the machine.
So the choice between a Workstation install and a Server install comes down to what you will be doing with the computer. If you are only interested in setting up a system for you to explore, then a workstation is probably the right choice. This machine is not likely to be running all the time, or heavily loaded for long periods of time. If on the other hand, you are creating a machine to manage the network in your home, or office, you would probably want the Server install. A server tends to handle scheduled tasks more than interactive tasks. For example a server is likely to do backups on a schedule, or download and parse email, or provide music to other computers in the house. In other words, it is designed to be running all the time with work to do at all hours of the day.
Be aware that a workstation can be a server for some tasks, and a server can be used as a workstation when needed. A more telling difference comes in what applications you install on it. We will discuss that next.
So the Question remains, how do I decide what I want to install?
The best answer to the question, unfortunately is another question. What do you want to do with the computer? By looking at what you want to do with the computer you can decide what type of installation to do.
In addition to deciding what you plan to do with your computer, you might want to make other decisions. You see Linux is different than windows, in that you seldom install everything which comes on the install CD. This is not to say that you can’t, it is more to say that you probably don’t want to install everything. For example, when you install windows 2000, you get the OS, the Media Player, Web Browser, and Outlook email program.
When you install many versions of Linux it will ask you if you want to install a specific functional group of programs. This is illustrated in this screen shot from the Mandrake 10 install:
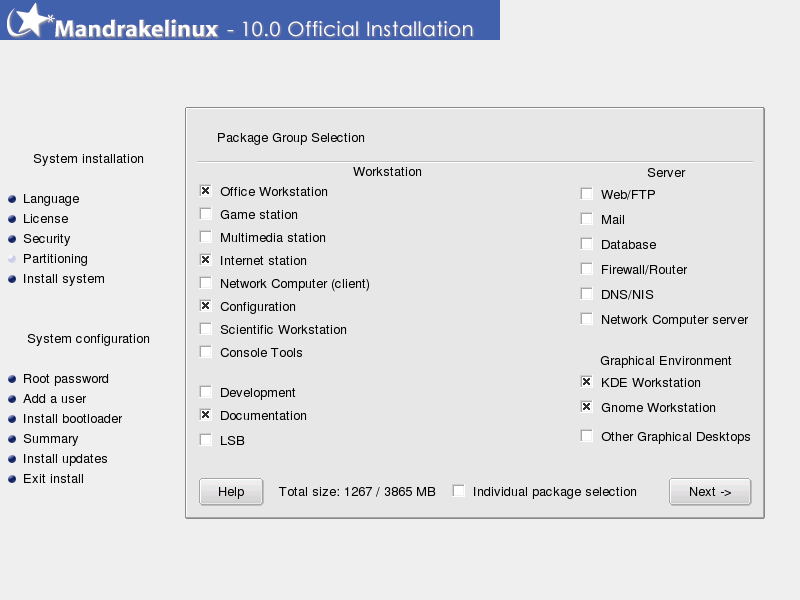
What this screen shows is two types of systems, workstations and servers, plus your choice of window managers. Under each of these types it lists package groups for specific functions. Now lets suppose you decide to you want to install a workstation build, but you want the database package install. No problem, just select Database from the server side and it will load those packages also. This customization is normal under Linux.
Now I am sure some of you are confused. Lets suppose you were installing Window XP and you wanted to set it up for use in a home office. Lets suppose you want Word Processing, Spreadsheets, Simple Accounting, Calculators, PDF creator, and a Desktop Publishing tool. You would probably install Windows XP, or more likely purchase a computer with it already installed. They you would purchase and install Microsoft Office, Quicken, Adobe Distiller (to create PDF file), and Adobe Page Maker for (desktop publishing). For the moment we will ignore the cost of these program, as thought that did not matter. So you purchase these 4 products, and install them.
OK, we have seen how it is done in Windows. Now suppose you wanted to do the same using Mandrake Linux Version 10. You would just select the package group Office. The programs included in that group include Open Office for your work processing and spreadsheet, GNUCash for simple accounting, Qcalculate for calculations, Nothing for PDF creation since it is included in Open Office, and Scribus for Desktop Layout. So you see you could get all the software for the defined office from the Mandrake install CDs. See the link below for a full list of what is included on the Mandrake Linux Packages. Note the first link is a copy of the original page so it will not change if Mandrake updates their web page. The second link is the actual link on the mandrake site. Go there if you want the package explanations they provide.
Mandrake Version 10 Package list This is copied from: http://www.mandrakesoft.com/products/101/x86-64/packages
So the package groups are just a method of adding functionality to your Linux system without needing to find and install additional software on your system. Now you might notice that the package groups contain more than on program. What if you want to select only some of the programs included in a package group instead of the entire group? Well that facility is provided by the installer:
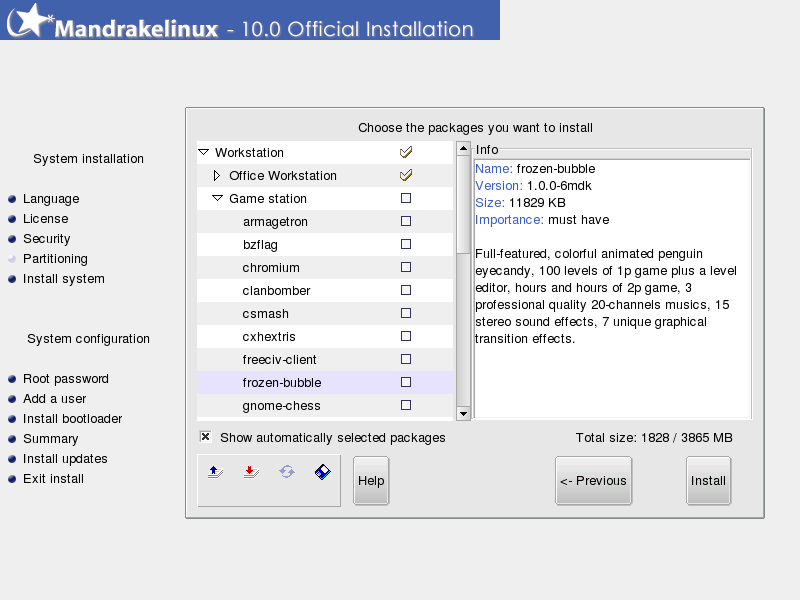
This level of install takes more time, but gives you the ability to fine tune your system at the program level. The only down side is that you might be wading through a VERY LONG List of programs. The package list for Mandrake Linux Version 10 lists 4674 programs you can select from. If you want a REALLY long list of available packages, try Debian Testing install, it contains 16343 packages. Don’t believe me check out this text file.
What if I want to change the install later?

Well, lets consider how you would deal with this question under Windows first. Suppose you wanted to add a block drawing program to your Window XP system. First you would need to find a program to perform this function. A logical choice would be something like Visio. This allows you to do block drawings of things like a network setup, or logic flow. So you purchase the program, then run the CD install program and finally reboot the system to finish the install.
Lets assume you did a search on the internet and found a program named Dia, which is a Linux block drawing program. After checking the package list above, you notice it is part of the Office package. Under Mandrake, you would start the program RpmDrake select the install icon, and go to the Office package group. From here select dia, and tell it to install the software. Easy No? The installed is even smart enough to install other programs which are needed as dependencies. This was a problem with some of the earlier install programs such as RPM. You would download a program and try to install it, only to find that it depended on some other program you had not yet installed. This used to be called RPM Hell since it could be frustrating. But the newer generation of installers understand how to resolve these issues during the install.
One additional feature of the install programs line RpmDrake is that they can work with packages from repositories on the internet. So, if you have a reasonable internet connection, you can use an installer to download and install a program, as well as use the initial CDs.
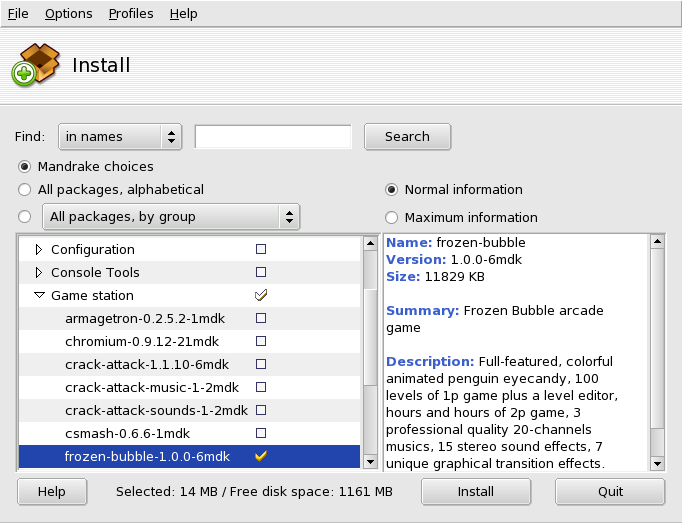
What if I want to remove software from my system? The answer is to simply use RpmDrake and select the remove option. What could be simpler.
What happens if I try to remove a program, which has other programs depending on it? The answer is that you will be warned. All the package managers, as far as I know, will inform you before removing a package which has other packages depending upon it. Of course, this is Linux, so if you say, go ahead, you could end up with a non-working program or system. But play with fire, and sometimes you will get your fingers burned.
Now I am not telling you that using a package manager will cause you to crash your system. A lot of thought went into these tools, and they are reasonably fool proof. They are built to help you manage a system, so that is the best method to modify your system. I am just pointing out that you are in control, after all this is Linux you know.
Postscript and Printers.

We will start by discussing what is Postscript and what can be done with it. For those of you who are curious, the tiger above came from a Postscript file. Have a look at you system with the command “locate tiger.ps”. There is a good chance that it is on your computer. If so, you can open it up with Ghostview to see it for yourself.
Postscript Definition:
A page description language based on work originally done by John Gaffney at Evans and Sutherland in 1976, evolving through “JaM” (“John and Martin”, Martin Newell) at XEROX PARC, and finally implemented in its current form by John Warnock et al. after he and Chuck Geschke founded Adobe Systems, Inc. in 1982.
Postscript is an interpreted, stack-based language (like FORTH). It was used as a page description language by the Apple LaserWriter, and now many laser printers and on-screen graphics systems. Its primary application is to describe the appearance of text, graphical shapes, and sampled images on printed or displayed pages.
A program in Postscript can communicate a document description from a composition system to a printing system in a device-independent way.
Postscript is an unusually powerful printer language because it is a full programming language, rather than a series of low-level escape sequences. (In this it parallels Emacs, which exploited a similar insight about editing tasks). It is also noteworthy for implementing on-the fly rasterisation, from Bezier curve descriptions, of high-quality fonts at low (e.g. 300 dpi) resolution (it was formerly believed that hand-tuned bitmap fonts were required for this task).
PostScript’s combination of technical merits and widespread availability made it the language of choice for graphical output until PDF appeared.
The Postscript point, 1/72 inch, is slightly different from other point units.
— Source.
Postscript is a Font technology created by Adobe. It is an interesting departure from your normal printing in that the font rendering is done by the printer not the computer. Rendering refers to converting a letter into the dot pattern you see on the paper. Basically Postscript is a font language which describes how a page will look. Postscript is some times referred to as a Page Description Language.
One interesting feature of Postscript is that the fonts are described mathematically. So instead of giving a bit map of what a letter looks like at a specific size, the adobe fonts, are really a math representation of what the font looks like. One result of this is that the fonts only need one copy for each font. ie. instead of having a bitmap for Times Roman at 12 points, and another for Times Roman at 15 points, there is only Times Roman. The font size is handled on the fly by the printer. Additionally the density of the font is done on the fly. So the same file can be printed at 150 dpi for an inkjet printer, or 4800 dpi for a high resolution printer.
Postscript is really a programming language which is interpreted by the printer to create the image we will eventually see on the paper. When Adobe created Postscript they effectively gave away the specs to the language. For those of you curious here is a PDF file detailing Postscript® LANGUAGE REFERENCE third edition as published by Adobe. This encouraged companies to implement postscript. Of course Adobe got a cut of the final product by licensing the technology. But it also meant that a lot of people could make use of the power of the language.
Another interesting point, is that the postscript files, are really all ASCII characters. So you could view a postscript file. Better yet you can even write them directly. So without further ado lets try a tutorial on writing Postscript.
What can I do with Postscript files?
Because Postscript has been available for a while, a number of tools are available to allow you to manipulate it. On this computer alone I have the programs:
psbook, psselect, pstops, epsffit, psnup, psresize,
psmerge, fixscribeps, getafm, fixdlsrps, fixfmps, fixmacps,
fixpsditps, fixpspps, fixtpps, fixwfwps, fixwpps,
fixwwps, extractres, and includeres
So what are these tools good for? Well suppose I have a pdf file I want to print, and it is 12 pages long. Now I could print it on 12 pieces of paper, but I would like it more compact, to use less paper and make it easier to carry around. Here are the steps I would use to create a minature book of it.
Using Acrobat reader I would print the book to a file. Lets call it print1.ps.
Next I would use psbook print1.ps print2.ps to convert the file into a set of book type pages. ie. once printed I will be able to fold it in half like a book.
Next I would use psselect -o -r print2.ps | lpr -Pps to print the Odd pages in reverse order. Once these pages are printed, I would turn over the stack and place it in the input tray 2. Then I would use psselect -e print2.ps | lpr -Pps to print the other side of the pages.
Finally, I would fold the pages in half to give me a book size 5 1/2 by 8 1/2 using only 3 sheets of paper printed on both sides. I only used a single sided printer and the postscript programs available.
Why is Postscript used in Linux?
I suppose the answer goes back to the original Unix machines. Remember when Unix was first created, the computers were not very powerful. So any work which could be off loaded to some other processing tool was appreciated. Since postscript is handled by the printer not the computer it made sense to use use postscript so they did not need to do the rendering on the CPU. Another advantage of postscript was that it was not printer specific. Since you could send a postscript file to any printer, it simplified the task of printer drivers. Just connect the printer and send it postscript. That way it was up to the printer to correctly render it for itself. And finally, since postscript files are ASCII, that appealed to the Unix authors who liked to use ASCII files instead of binary files.
I suppose you are wondering why we need to continue using postscript with printers today, since we have much more powerful computers. I would say it might have more to do with momentum than anything else, but postscript still fills the bill as a printer format medium. With current versions of Linux they even use the Ghostscript rendering engine to convert postscript files to bit maps before sending the output to some printers. That is one of the interesting things about Linux. It adapts to it’s environment.
Today, I find I still use Postscript files, partially as an intermediary file. If I write a letter or an article in TeX, I convert it to Postscript to view on the screen before I print it. Once it looks OK on line, I can then send it to the printers and get pretty much what I expect.
For those of you who have not already guessed PDF is really postscript version 4. PDF files are probably the best method of distributing a file where the formatting is important. Since Adobe has created Acrobat readers for most computer systems, and gives it away for free, it is hard to resist. But if you have a problem with using Acrobat Reader, you can use Ghostview or Xpdf to read the documents.
On the point of distributing files, another advantage in Linux is that Open Office will produce PDF files directly, so you do not need the Adobe Distiller program to convert files into PDF format. There also is the program ps2pdf, although I do not think the output is all that good. So you can work with PDF files with out ever using Adobe products.
Another interesting use of postscript is to capture the output of a program. Let me explains. Suppose you are working on windows and you have table from a Microsoft Project file you want to email to someone. You don’t want to email the whole project plan, and your friend does not own Project anyway. If you were clever and downloaded and installed the postscript printer driver from Adobe, you could print to a file, and then email the file to your friend. The trick is to install the generic postscript printer driver, and set it’s output a file instead of a printer. You can find the Generic Postscript driver at Adobe Postscript Driver for Windows..
Working with Cups
One of the programs common in Linux today is the Cups (Common Unix Printing System) printer driver. This system has taken over from many other printer control programs under Linux.
Background
Printing within UNIX has historically been done using one of two printing systems - the Berkeley Line Printer Daemon (“LPD”) [RFC1179] and the AT&T Line Printer system. These printing systems were designed in the 70’s for printing text to line printers; vendors have since added varying levels of support for other types of printers.
Replacements for these printing systems have emerged [LPRng, Palladin, PLP], however none of the replacements change the fundamental capabilities of these systems.
Over the last few years several attempts at developing a standard printing interface have been made, including the draft POSIX Printing standard developed by the Institute of Electrical and Electronics Engineers, Inc. (“IEEE”) [IEEE-1387.4] and Internet Printing Protocol (“IPP”) developed by the Internet Engineering Task Force (“IETF”) through the Printer Working Group (“PWG”) [IETF-IPP]. The POSIX printing standard defines a common set of command-line tools as well as a C interface for printer administration and print jobs, but has been shelved by the IEEE.
The Internet Printing Protocol defines extensions to the HyperText Transport Protocol 1.1 [RFC2616] to provide support for remote printing services. IPP/1.0 was accepted by the IETF as an experimental Request For Comments [RFC] document in October of 1999. Since then the Printer Working Group has developed an updated set of specifications for IPP/1.1 which have been accepted by the IETF and are awaiting publication as proposed standards. Unlike POSIX Printing, IPP enjoys widespread industry support and is poised to become the standard network printing solution for all operating systems.
CUPS uses IPP/1.1 to provide a complete, modern printing system for UNIX that can be extended to support new printers, devices, and protocols while providing compatibility with existing UNIX applications. CUPS is free software provided under the terms of the GNU General Public License and GNU Library General Public License.
— Source
Cups printing system Block diagram.
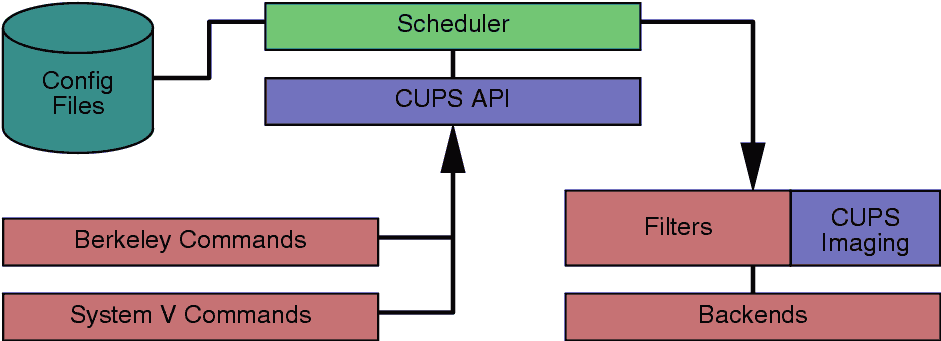
The Cups system is a fairly complete implementation of print handling in a standard way. For more information about Cups go to Cups Documentation.
To give you an idea how extensive the Cups system is, here are the man pages which come with it.
man accept man backend man classes.conf man cupsaddsmb
man cups-config man cupsd man cupsd.conf man cups-lpd
man cups-polld man cupstestppd man enable man filter
man lpadmin man lpc man lp man lpinfo
man lpmove man lpoptions man lppasswd man lpq
man lpr man lprm man lpstat man mime.convs
man mime.types man printers.conf
The basic idea is that Cups has created an integrated method for handling all the print chores. This extends from simply spooling a file, to prepossessing a file based on it’s file type. Yes Cups can look at an incoming file, figure out it’s type and apply the appropriate filter to the file before it goes to the printer.
Scheduler
The scheduler is a HTTP/1.1 server application that handles HTTP requests. Besides handling printer requests via IPP POST requests, the scheduler also acts as a full-featured web server for documentation, status monitoring, and administration.
The scheduler also manages a list of available printers on the LAN and dispatches print jobs as needed using the appropriate filters and backends.
Configuration Files
The configuration files consist of:
The HTTP server configuration file.
Printer and class definition files.
MIME type and conversion rule files.
PostScript Printer Description (“PPD”) files.
The HTTP server configuration file is purposely similar to the Apache server configuration file and defines all of the access control properties for the server.
The printer and class definition files list the available printer queues and classes. Printer classes are collections of printers. Jobs sent to a class are forwarded to the first available printer in the class, round-robin fashion.
The MIME type files list the supported MIME types (text/plain, application/postscript, etc.) and “magic” rules for automatically detecting the format of a file. These are used by the HTTP server to determine the Content-Type field for GET and HEAD requests and by the IPP request handler to determine the file type when a Print-Job or Send-File request is received with a document-format of application/octet-stream.
The MIME conversion rule files list the available filters. The filters are used when a job is dispatched so that an application can send a convenient file format to the printing system which then converts the document into a printable format as needed. Each filter has a relative cost associated with it, and the filtering algorithm chooses the set of filters that will convert the file to the needed format with the lowest total “cost”.
The PPD files describe the capabilities of all printers, not just PostScript printers. There is one PPD file for each printer. PPD files for non-PostScript printers define additional filters through cupsFilter attributes to support printer drivers.
CUPS API
The CUPS API contains CUPS-specific convenience functions for queuing print jobs, getting printer information, accessing resources via HTTP and IPP, and manipulating PPD files. Unlike the rest of CUPS, the CUPS API is provided under the terms of the GNU LGPL so it may be used by non-GPL applications.
Berkeley and System V Commands
CUPS provides the System V and Berkeley command-line interfaces for submitting jobs and checking the printer status. The lpstat and lpc status commands also show network printers (“printer@server”) when printer browsing is enabled.
The System V administation commands are supplied for managing printers and classes. The Berkeley printer administration tool (lpc) is only supported in a “read-only” mode to check the current status of the printer queues and scheduler.
Filters
A filter program reads from the standard input or from a file if a filename is supplied. All filters must support a common set of options including printer name, job ID, username, job title, number of copies, and job options. All output is sent to the standard output.
Filters are provided for many file formats and include image file and PostScript raster filters that support non-PostScript printers. Multiple filters are run in parallel to produce the required output format.
The PostScript raster filter is based on the GNU Ghostscript 5.50 core. Instead of using the Ghostscript printer drivers and front-end, the CUPS filter uses a generic raster printer driver and CUPS-compliant front-end to support any kind of raster printer. This allows the same printer driver filter to be used for printing raster data from any filter.
CUPS Imaging
The CUPS Imaging library provides functions for managing large images, doing colorspace conversion and color management, scaling images for printing, and managing raster page streams. It is used by the CUPS image file filters, the PostScript RIP, and all raster printers drivers.
Backends
A backend program is a special filter that sends print data to a device or network connection. Backends for parallel, serial, USB, LPD, IPP, and AppSocket (JetDirect) connections are provided in CUPS 1.1.
SAMBA version 2.0.6 and higher includes a SMB backend (smbspool(1)) that can be used with CUPS 1.0 or 1.1 for printing to Windows.
— Source
One interesting fact I learned is that you can configure Cups using a Web browser. Go to the URL: http://localhost:631
Written by John F. Moore
Last Revised: Tue 01 Sep 2020 08:10:11 PM EDT

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 3.0 Unported License.